I started writing this article around January 2022 but never got around publishing it. Given its September already, I’m going ahead and publishing the draft. This is not intended to be read/shared but to just keep this blog going.
I have been playing wordle continously for the past week with my colleagues. It’s a simple game where you guess a five letter word within six chances. At each guess, the game tells you how many letters you got right, how many letters are in the word in a different position, and how many aren’t present in the answer. The game gives you a new puzzle everyday. The game became so popular that even google added an easter egg.

As I started getting into the game, I thought to myself, would it be cheating if I looked up for words in a dictionary? I felt given english was my second language, I was already in a minor disadvantage so until I don’t explicitly lookup the solution, what’s the big deal, right? I then thought if I am going to simple look upto a dictionary and use each guess to eliminate words, why not write a script to do it? After all, the script would be literally doing what I would do right? Right now, I didn’t know where it stops being fair and where it starts to become cheating but write a simple solver for the game sounded like a fun weekend project.
Initially, I started breaking down the game into its logical components. The game only allows legitimate words as its guesses which means, “aeiou” isn’t a valid guess. Futhermore, looking into the game’s source code, the front end comes bundled with two lists of possible words. The combines to 12972 words. With some further research, I figured the game only uses the first list, which contains all the most common words, which even brings down the total search space to 2315 words.
Even with 2315 words, with random guessing, I still only got 6/2315 chances. You don’t have to be an expert in math to know that a very slim chance. So, to further reduce my search space, I implemented the game’s rules into a pruning function. Each time when a word is guessed, the rule engine builds a set of all correct, partial, and wrong guesses. It then goes through the list and prunes it. This was much efficient than I thought.
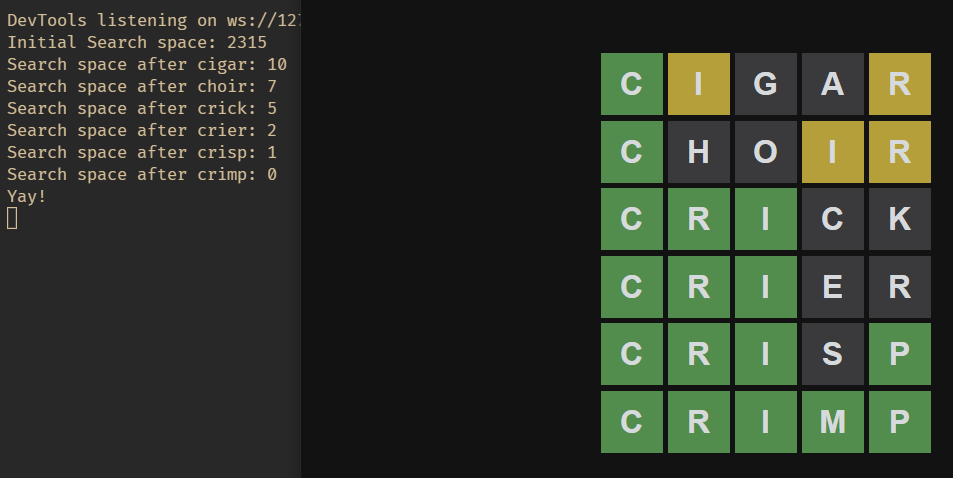
Well, a simple algorithm to prune the possible set of words did the job. However, taking so many tries to solve the puzzle is still inefficient. Taking a deep look into it, the major issue I found was when there is more than one possbile word that can be used for the current guess, the algorithm simply selects the first option. When I solve it, I usually use words like “adieu” as my starters as they can elimate a ton of words by figuring out which vowels to use. “adieu” does not exist in the list but just simple adding it as the first guess significantly improves the search attempts.
The reason “adieu” did better was because it had 4 out of 5 vowels in the english language. Almost all of the words in my dataset had vowels in them.
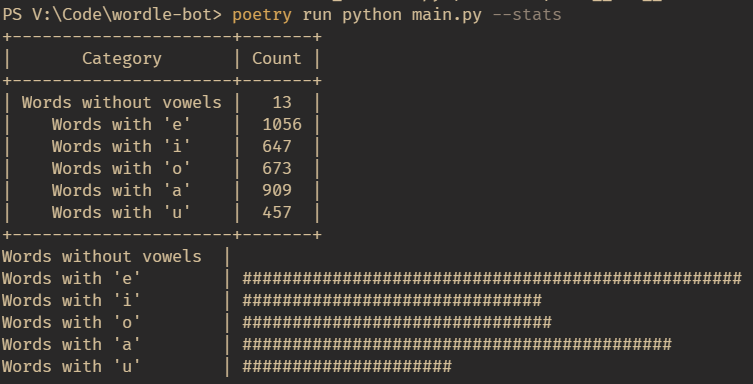
I wrote a simple script to generate word count for each vowel and consonant and a histogram to visually represent it.
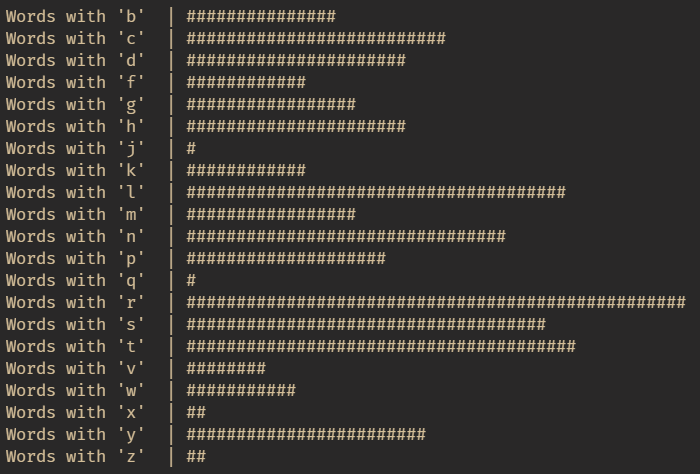
I came with a simple heuristic: Almost all words have vowels in them and given consonants have their distribution too, if I could come up with a heuristic weight for each of the word and sort them using that, each guess would elimate the as many words as possible. With this idea, I wrote a simple function to order each letter based on its occurence and generated a weight for each word using the sum of the letter order. This way, the heaviest must have the most used letters.

This improve search time by miles but without actually quantifying it, it is simply an ancedotal data. A simple script to generate number of guesses for all words shows there are two words that require ten guesses and in total 148 words that require over 6 attempts. So, the algorithm doesn’t always win. This can be probably improved by using a relative heuristic where the words are not only sorted by the occurence order of each letter but also the relative distance between the letters. As in, if x has 10 occurence and then next most y has 100, the heuristic weight should reflect the distance. However, I want to stop here and maybe leave that as a homework for you :p. adieu!
Source: AravindVasudev/wordle-bot